|
1
|
- Ein Projekt, das die Welt hätte verändern sollen, und eine kurze
Einführung in einem spannenden Forschungsgebiet
|
|
2
|
- Im realen Leben, z.B. gleichzeitig Zähne putzen, Mickey Mouse lesen und
sich anziehen
- Spätenstens in der Schule merkt man, dass der Kleiderhaken in der Jacke
geblieben ist
- Auf einem Supercomputer: man löse die Laplace-PDE auf einem Polygon, in
parallel, mit einem iterativen Jacobi-Verfahren
- Kommunikation zwischen den Knoten so klein wie möglich halten!!
Ansonsten je mehr Prozessoren, desto langsamer…
|
|
3
|
- Man definiert eine fixe Anzahl (=p) Prozessoren, bevor das Programm auf
dem Supercomputer ausgeführt wird.
- OpenMP: Compiler übernimmt die gesamte Aufgabe der Parallelisierung (Der
Programmierer muss nur Direktiven angeben)
- MPI (Message Passing Interface): Der Programmierer muss die
Kommunikation zwischen den Knoten selbst definieren.
- Meistens wird aber ein Programm geschrieben, und das Programm wird
mehrmals mit verschiedenen Anfangsparametern gestartet!!
|
|
4
|
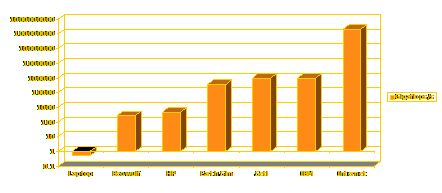
- Dieser Laptop führt etwa eine halbe Milliarde Operationen pro Sekunde
aus = ½ GigaFlop, das war die Leistung eines Supercomputers vor 10
Jahren
- Ein Supercomputer mit Shared Memory (= alle Prozesse greifen auf dem
gleichen Speicher zu), etwa 470 Gigaflops (HP Superdome)
- Linux Beowulf Cluster mit Distributed Memory und 502 Prozessoren (jeder
Prozess hat eigenen Speicher), etwa 266 Gigaflops
|
|
5
|
- Der japanische Supercomputer Earth Simulator rechnet mit 35 Teraflops
(=35000 Gigaflops)
- Das Projekt Seti@home, der erste erfolgreiche Grid - Computing Projekt
rechnet mit 43 Teraflops
|
|
6
|
- Mehr als 80% der Rechenzeit einer CPU besteht aus dem Warten von
Benutzereingaben…
- Heutige Betriebssysteme können in dieser Zeit Prozesse im Hintergrund
laufen lassen, ohne dass der Anwender etwas merkt
|
|
7
|
- Wenn alle Computer auf der Welt in einem Cluster zusammengefügt würden,
welche Leistung könnte man dann teoretisch erreichen??
- 400 Millionen Rechner à ½ Gigaflop = 200 Millionen Gigaflop = 200 000
Teraflop = etwa 2000 Supercomputer!
|
|
8
|
|
|
9
|
- Ein alter Supercomputer verteilt Datensätze eines Radioteleskopes an
normale Rechner.
- Auf diese Rechner ist ein kleines Programm installiert, das die
Datensätze im Hintergrund analysiert
- Die Analyse erfolgt mit einer langwierigen Fouriertransformation, das
Ergebnis der Analyse wird dann an den alten Supercomputer
zurückgeschickt
- Alle können beim Projekt mitmachen! Sogar ein 80486!
|
|
10
|
- United Devices, wie Seti@home, verteilt Datensätze, die von normalen
Rechnern im Hintergrund verarbeitet werden.
|
|
11
|
- Bei diesen beiden Projekten, Seti@home und Krebsforschung, die über
Internet laufen, ist die Anzahl beteiligter Prozessoren (=p) am Anfang
nicht im voraus bestimmt… Rechner können vom Projekt ein und aussteigen…
- Unterschied gegenüber MPI und OpenMP!!
|
|
12
|
- Client / Server
- Beispiele: Seti@home, Krebsforschung
- Peer to peer Netwerk
- Beispiele: Kazaa, Gnutella, GPU, a @lobal processing unit??
|
|
13
|
|
|
14
|
- Idee aus Simulationen eines Teams der Princeton University
|
|
15
|
- Rechner im Internet lassen GPU laufen. GPU verbindet sich automatisch zu
einem Peer to Peer – Netzwerk
- GPU stellt wissenschaftliche Bibliotheken zur Verfügung
- Jeder, der GPU installiert hat, kann auch mal andere Rechner verwenden,
um eine eigene verteilte Berechnung auszuführen
|
|
16
|
- GPU ist in 3 Teile gegliedert
- Der Routing Layer leitet Berechnungspakete weiter
- Eine virtuelle Maschine interpretiert die Berechnungspakete mit Hilfe
einer Bibliothek von Plugins
- Plugins sind kompilierte DLLs, die die Funktionalität des Knotens
erweitern
|
|
17
|
- Die polnische Notation wird eingeführt, um die virtuelle Maschine zu
vereinfachen 1 + 1 wird zu 1,1,+
- Berechnungspakete werden als Dateisuche getarnt, z.B eine Dateisuche für
„GPU:1,1,+“ wird als Berechnungsaufgabe interpretiert
|
|
18
|
- Zwei Bibliotheken (Pi – Berechnung und verteilte Berechnung des
diskreten Logarithmus)
- Prototyp kann man von Internet herunterladen http://sourceforge.net/projects/gpu
|
|
19
|
- Version 0.688 implementiert alles, was in der Dokumentation beschrieben
wird… ist aber sehr instabil
- Version 0.768 ist sehr stabil (dank dem Komponenten TGnutella von Kamil
Pogorzelski), Ergebnisse werden (noch) nicht zurückgesandt.
|
|
20
|
|
|
21
|
|
|
22
|
- Global Grid Forum www.gridforum.org
- EU Grid: http://eu-datagrid.web.cern.ch
- Top 500 Supercomputer: http://www.top500.org
- Seti@home http://setiathome.berkeley.edu
- Krebsforschung http://members.ud.com/projects/cancer
|
|
23
|
|

 Notizen
Notizen{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}