|
1
|
- Un projet qui pourrait changer le monde, et une courte introduction à un
intéressant domaine de recherche.
|
|
2
|
- Par exemple, cela revient à essayer de se brosser les dents, lire Mickey
et s’habiller en même temps
- Plus tard, en arrivant à l’école, on s’aperçoit que le cintre est
toujours dans la veste.
- Sur un superordinateur, l’EDP de Laplace est résolue sur un polygone, en
parallèle avec une méthode de Jacob itérative.
- La communication entre les nœuds doit être la plus courte possible ! Sinon,
plus il y aura de processeurs et plus le calcul prendra de temps…
|
|
3
|
- Le nombre de processeurs est défini avant que le programme soit exécuté
sur le superordinateur.
- OpenMP : Le compilateur s’occupe de toute la « parallélisation » (le
programmeur ne fait que donner des instructions).
- MPI (Message Passing Interface) : C’est le programmeur qui décide de la
façon dont les nœuds communiquent.
- Mais la plupart du temps un programme est simplement écrit, puis exécuté
plusieurs fois avec des paramètres initiaux différents !
|
|
4
|
- Cet ordinateur calcul environ un demi millions d’opérations par seconde
= ½ gigaflop ; cela correspond à la puissance d’un superordinateur d’il
y a 10 ans.
- Un superordinateur avec une mémoire partagée (tous les calculs sont
effectués dans le même espace mémoire) : à peu près 470 gigaflops (HP Superdome)
- Linux Beowulf Cluster avec une mémoire distribuée et 502 processeurs
(chaque calcul a son propre espace mémoire) : à peu près 266 gigaflops
|
|
5
|
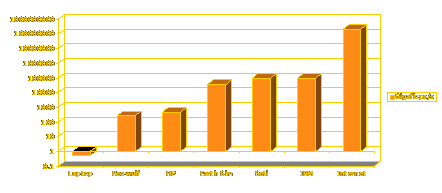
- Le superordinateur Japonais « Earth Simulator » calcule à 35 teraflops
(35000 gigaflops)
- Le projet Seti@home, le premier projet de calcul distribué, atteint 43
teraflops
|
|
6
|
- Un CPU passe plus de 80% de son temps à attendre des instructions…
- Les systèmes actuels pourraient exécuter des programmes en arrière-plan
sans aucun changement pour l’utilisateur
|
|
7
|
- Si tous le ordinateurs du monde étaient reliés, quelles performances
pourrait-on théoriquement atteindre ?
- 400 millions d’ordinateurs à ½ gigaflop = 200 millions de gigaflops =
200 000 teraflops = à peu près 2000 supercalculateurs !
|
|
8
|
|
|
9
|
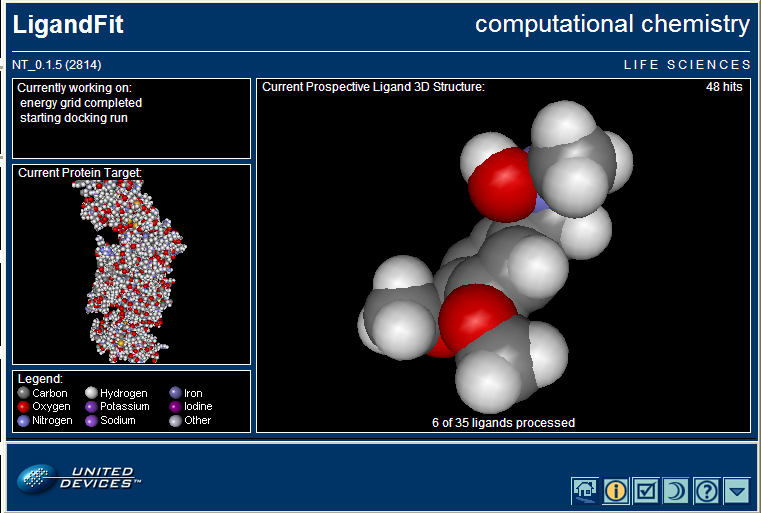
- Un ancien supercalculateur distribue les données d’un radiotélescope à
des ordinateurs ordinaires
- Un petit programme installé sur ces ordinateurs analyse les données en
arrière-plan.
- L’analyse utilise une fastidieuse transformation de Fourier. Les
résultats sont ensuite renvoyés au superordinateur.
- Tout le monde peut participer au projet ! Même avec un 80486 !
|
|
10
|
- Comme Seti@home, United Devices distribue des paquets de données qui
sont ensuite traités en arrière-plan par des ordinateurs.
|
|
11
|
- Dans ces deux projets, Seti@home et Recherche contre le cancer, qui
fonctionnent tous les deux à travers d’Internet, le nombre de
processeurs (p) n’est pas défini à l’avance... Les ordinateurs peuvent se connecter
et se déconnecter lorsqu’ils veulent.
- C’est différent de MPI et d’OpenMP !
|
|
12
|
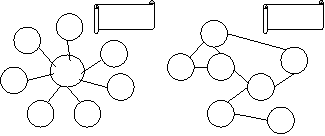
- Client / Serveur
- Exemples :
- Seti@home
- Cancer Research
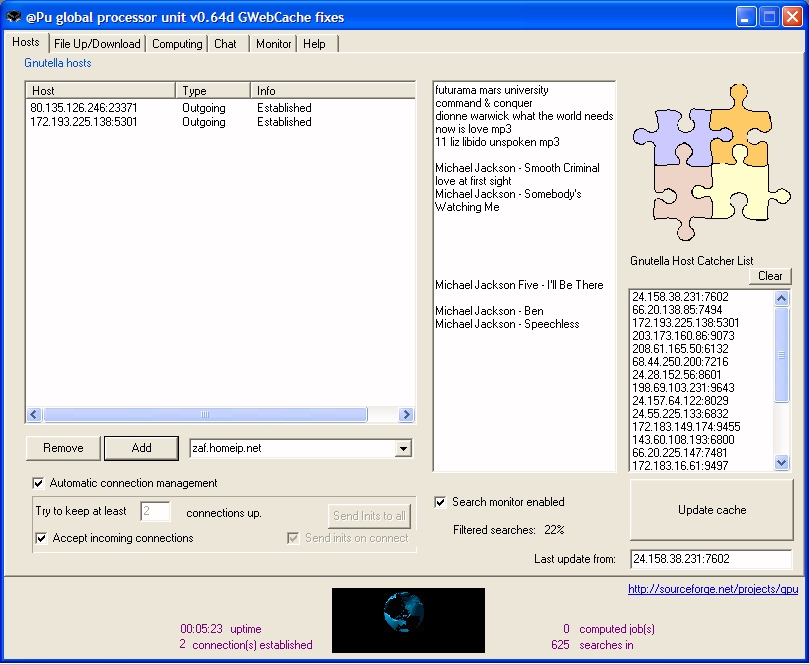
- Réseau « Peer-to-Peer »
- Exemples :
- Kazaa
- Gnutella
- GPU, a @lobal processing unit??
|
|
13
|
|
|
14
|
- Une idée venant de simulations faites par une équipe de l’Université de
Princeton
|
|
15
|
- Les ordinateurs connectés à Internet exécutent GPU. GPU se connecte
automatiquement à un réseau « peer-to-peer ».
- GPU propose une bibliothèque scientifique.
- Toutes les personnes qui possèdent GPU peuvent aussi utiliser les autres
ordinateurs pour effectuer leurs propres calculs distribués.
|
|
16
|
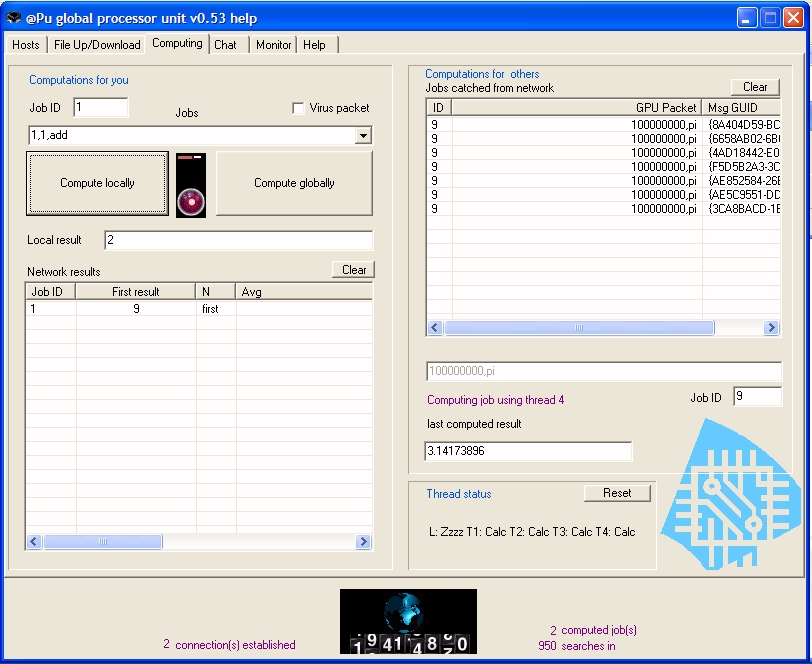
- GPU comporte trois parties
- Le « routing layer » transmet les paquets de calcul.
- Une machine virtuelle interprète ces paquets avec l’aide d’une
bibliothèque de « plugins ».
- Les « plugins » sont des DLL compilées, qui augmentent les
fonctionnalités du nœud.
|
|
17
|
- Pour simplifier la machine virtuelle, la notation polonaise est utilisée
: 1+1 devient 1,1,+
- Les paquets de calcul sont déguisés en recherche de fichiers : par
exemple une recherche de « GPU:1,1,+ » est interprétée comme le calcul
de 1+1.
|
|
18
|
- Deux bibliothèques (calculs de pi et du logarithme discret)
- Vous pouvez télécharger le prototype sur : http://sourceforge.net/projects/gpu
|
|
19
|
- La version 0.688 comporte tout ce qui est décrit dans la
documentation... mais elle est très instable.
- La version 0.768 est très stable (grâce à TGnutella, de Kamil
Pogorzelski). Mais les résultats ne sont pas (encore) renvoyés...
|
|
20
|
|
|
21
|
|
|
22
|
- Forum de Global Grid www.gridforum.org
- EU Grid: http://eu-datagrid.web.cern.ch
- Top 500 des supercalculateurs : http://www.top500.org
- Seti@home http://setiathome.berkeley.edu
- Cancer Research http://members.ud.com/projects/cancer
|
|
23
|
|

 Commentaires
Commentaires{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}